Video content comprehension is essential for various applications, ranging from video analysis to interactive systems. Despite advancements in large-scale vision-language models (VLMs), these models often struggle to capture the nuanced, spatiotemporal details essential for thorough video analysis.
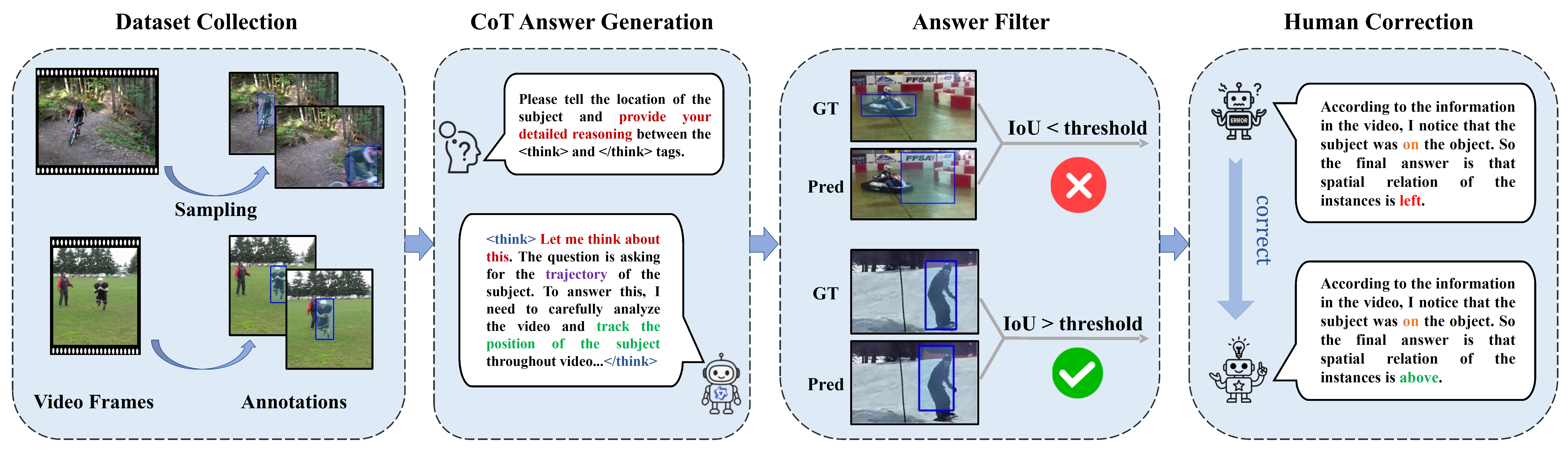
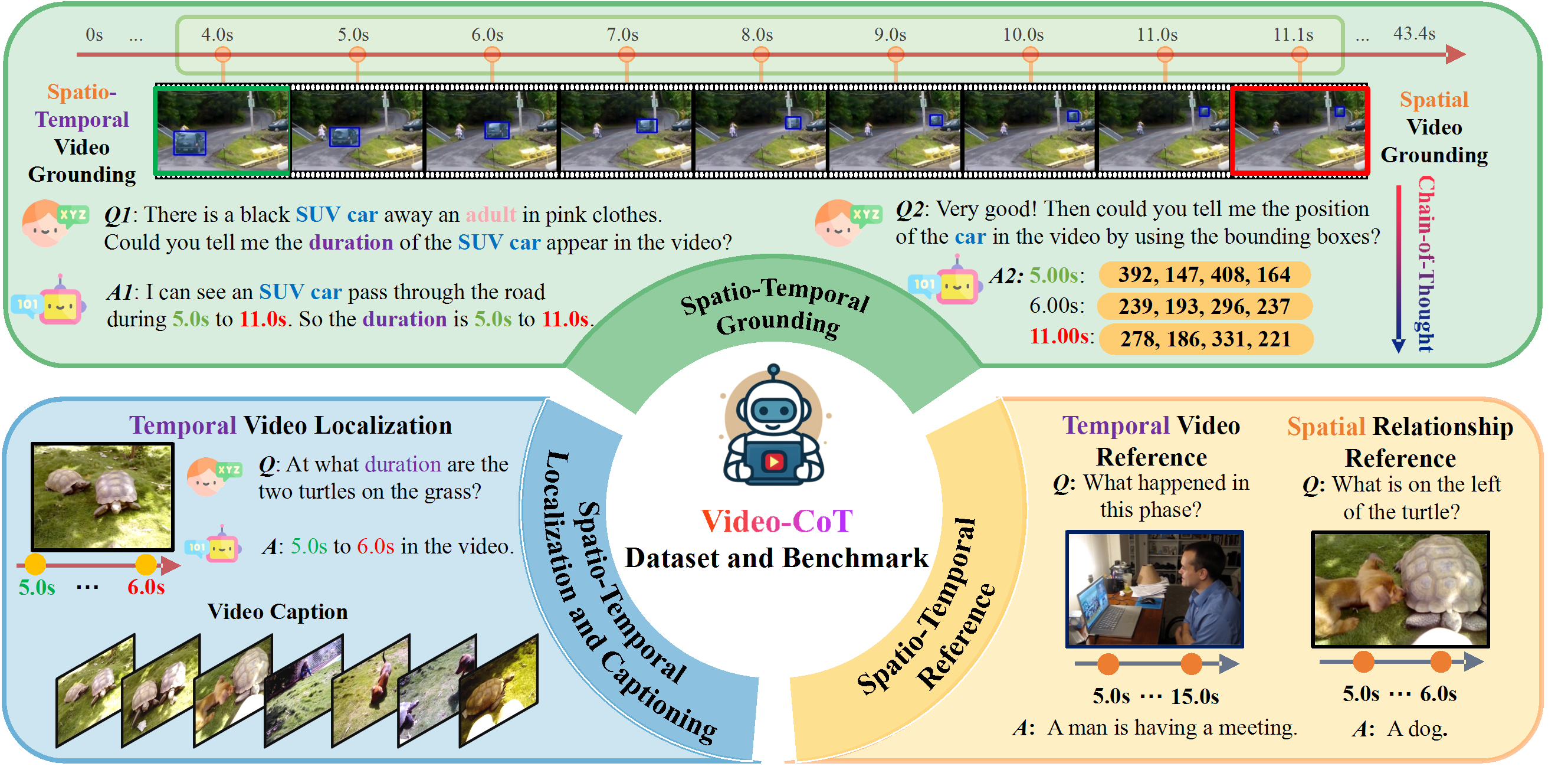
To address this gap, we introduce Video-CoT, a groundbreaking dataset designed to enhance spatiotemporal understanding using Chain-of-Thought (CoT) methodologies. Video-CoT contains 192,000 fine-grained spatiotemporal question-answer pairs and 23,000 high-quality CoT-annotated samples, providing a solid foundation for evaluating spatiotemporal understanding in video comprehension. Additionally, we provide a comprehensive benchmark for assessing these tasks, with each task featuring 750 images and tailored evaluation metrics.
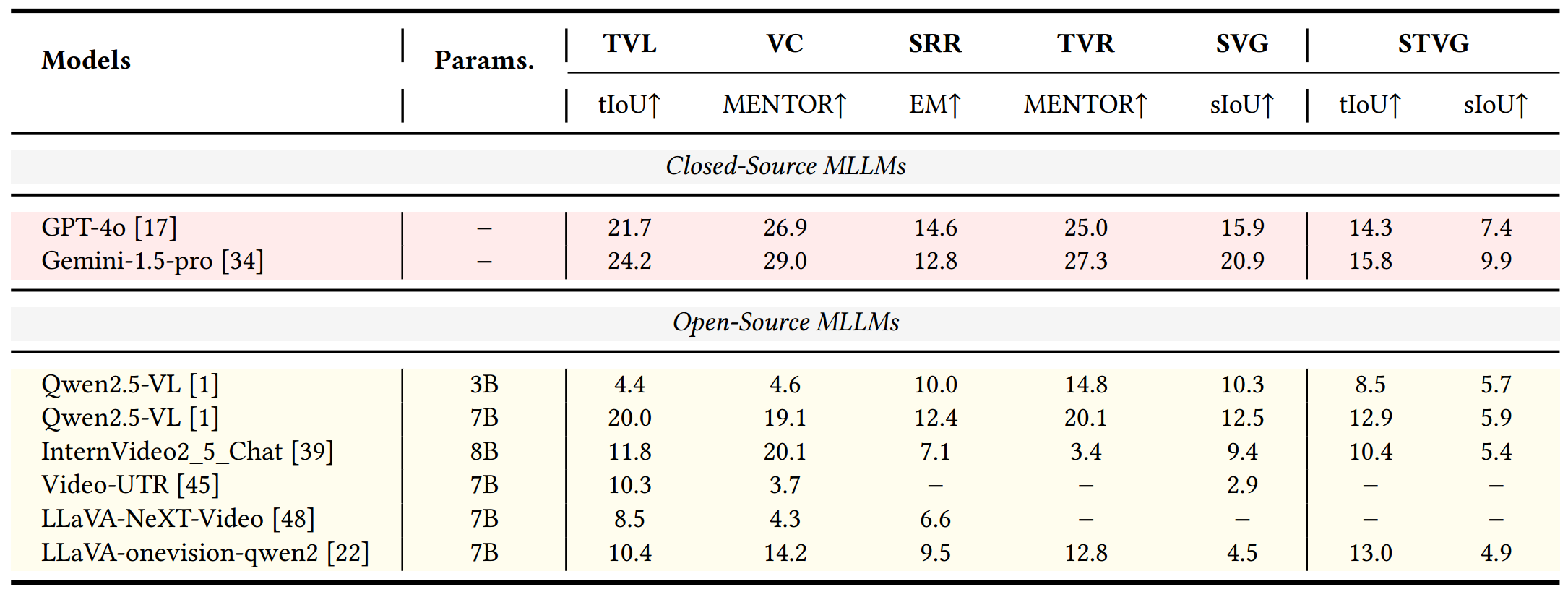
Our extensive experiments reveal that current VLMs face significant challenges in achieving satisfactory performance, highlighting the difficulties of effective spatiotemporal understanding. Overall, the Video-CoT dataset open new avenues for research in multimedia understanding and support future innovations in intelligent systems requiring advanced video analysis capabilities. By making these resources publicly available, we aim to encourage further exploration in this critical area.